Machine Learning Categories
Explore the different types of machine learning and understand when to use each approach
Machine Learning Categories
Machine learning algorithms can be organized into different categories based on their learning approach and the type of problems they solve. Understanding these categories helps in choosing the right algorithm for your specific use case and provides a framework for learning machine learning systematically.
Supervised Learning
Supervised learning is the most common type of machine learning where algorithms learn from labeled training data. The algorithm is provided with input-output pairs and learns to map inputs to outputs. This category includes both classification (predicting categories) and regression (predicting continuous values) problems. Examples include predicting house prices, classifying emails as spam/not spam, or recognizing handwritten digits.
Unsupervised Learning
Unsupervised learning algorithms work with unlabeled data and find hidden patterns or structures in the data. These algorithms don't have a specific target to predict but instead discover interesting patterns, groupings, or relationships in the data. Common applications include customer segmentation, anomaly detection, dimensionality reduction, and market basket analysis.
Classification
Classification algorithms predict discrete categories or classes for given inputs. They learn to assign labels to data points based on their features. Classification can be binary (two classes like spam/not spam) or multi-class (multiple classes like different types of animals). These algorithms are widely used in image recognition, text classification, medical diagnosis, and fraud detection.
Regression
Regression algorithms predict continuous numerical values based on input features. They model the relationship between dependent and independent variables to make predictions. Regression is used for forecasting sales, predicting house prices, estimating stock values, analyzing trends, and any scenario where you need to predict a continuous outcome. Linear regression is the most fundamental algorithm in this category.
Clustering
Clustering algorithms group similar data points together based on their features, without any prior knowledge of the groups. They identify natural groupings in the data, making it useful for customer segmentation, image segmentation, document organization, and anomaly detection. Popular clustering algorithms include K-means, DBSCAN, and hierarchical clustering, each with different approaches to defining similarity and forming clusters.
Ensemble Methods
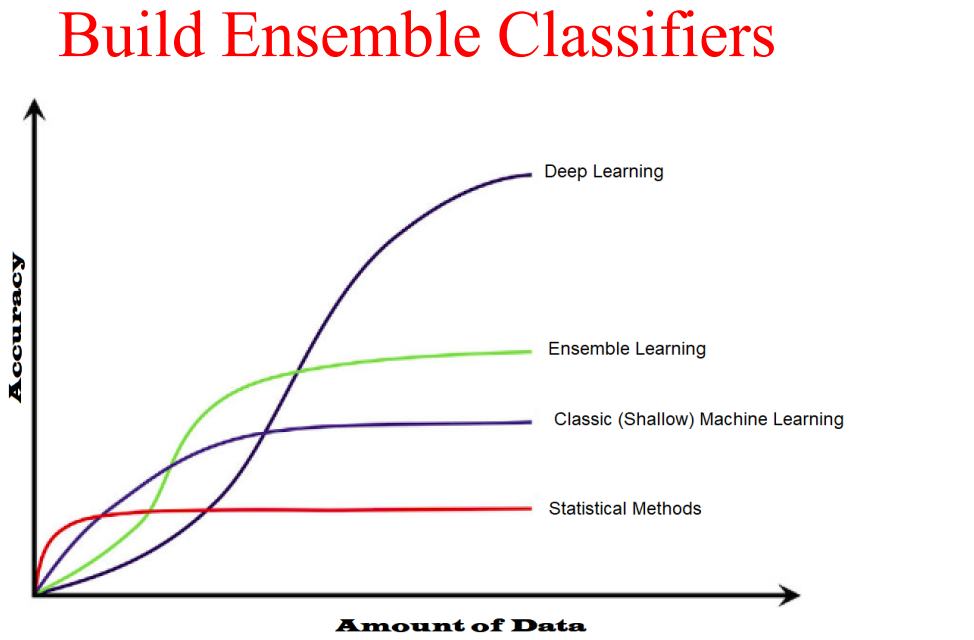
Ensemble methods combine multiple machine learning models to improve overall performance and reduce overfitting. They work on the principle that a group of weak learners can create a strong learner. Common ensemble techniques include bagging (Random Forest), boosting (AdaBoost, Gradient Boosting), and stacking. These methods are particularly effective for complex problems and often achieve state-of-the-art performance in competitions.
Deep Learning
Deep learning is a subset of machine learning that uses artificial neural networks with multiple layers to model and understand complex patterns in data. These networks are inspired by the human brain and can automatically learn hierarchical representations from raw data. Deep learning has revolutionized fields like computer vision, natural language processing, speech recognition, and autonomous systems. Popular architectures include Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Transformers.